서론
예전에 했던 프로젝트에서 fulltext 인덱스를 사용해 성능을 개선시켰던 경험을 담아 DB에 더미데이터를 넣어서 검색 성능을 비교하는 실험을 해보려고 한다. 보통 검색을 할 때 특정 키워드가 포함된 내용을 검색하려고 쿼리를 작성하려면 LIKE 를 사용해왔었다.
JPA에서도 검색 쿼리로 매핑하려고 할 때 4가지의 작성 방법으로 검색을 진행하는 편이다.
findPostByContentLike(String content);
findPostByContentStartingWith(String content);
findPostByContentEndingWith(String content);
findPostByContentContaining(String content);
해당 메소드들이 각각 쿼리로 변환되면 content인 열의 레코드를 찾거나 content로 시작하는, content로 끝나는, content가 들어있는 레코드를 찾게 될 것이다.
like :content
like :content%
like :%content
like :%content%
간편하지만 LIKE 쿼리의 가장 큰 단점은 FULL SCAN으로 실행될 수 있다는 점이다.
/* Full Scan */
SELECT * FROM POST WHERE CONTENT LIKE '%주식%';
SELECT * FROM POST WHERE CONTENT LIKE '%주식';
/* Index Scan */
SELECT * FROM POST WHERE CONTENT LIKE '주식%';RDB인 MYSQL는 B-Tree, B+ Tree로 인덱싱을 지원한다. B트리 특성상 리프노드의 데이터들은 사전순, 오름차순으로 정렬되어있다. 그렇기 때문에 '주식'으로 시작하는 내용은 범위 탐색이 되지만 '주식'이라는 단어가 들어간 본문이나 '주식'으로 끝나는 문장은 범위탐색이 불가능해 결국 FULL SCAN이 동작할 수 밖에 없는 구조이다.
단순히 100,1000개의 데이터에서 단어가 들어간 본문을 검색한다면 성능 이슈가 발생하진 않겠지만, 대규모 트래픽에서 많은 요청이 한꺼번에 들어오고 DB Connection POOL도 충분하지 않다면 미비하다고 느꼈던 해당 이슈가 문제로 돌아올 수도 있을 것이다.
본론
예전에 프로젝트때 검색 성능을 높이려고 사용했던 FULL TEXT INDEX와 단순 LIKE 쿼리의 성능 비교를 진행하려고 한다.
일단 WINDOW OS에 local 환경에서 mysql 서버를 실행시키고 더미데이터를 넣어보려고 한다.
검색을 조금 해보니 더미데이터를 삽입하는 방법에는 엑셀, bulk insert, mockaroo 등 방법이 있다고 하는데, MYSQL 8.0 이상부터는 CTE와 case 문을 이용해서 여러 문자가 담긴 content 컬럼을 만들어낼 수 있다고 해서 해당 방법을 채택해보려고 한다. 그 이유는 쿼리 문으로만 더미데이터를 만들어낼 수 있고 다른 서비스에 로그인하거나 부수적인 리소스가 들지 않는 방법이라고 판단했기 때문이다.
InnoDB 엔진의 id, title, content만 있는 테이블을 하나 생성했다. content 열은 TEXT 타입으로 적용했다.
CREATE TABLE IF NOT EXISTS posts (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT
)
ALTER TABLE POSTS ADD FULLTEXT INDEX FT (CONTENT) WITH PARSER ngram;

기본 parser는 공백을 기준으로 단어를 구분해서 파싱한다. 하지만 ngram parser는 하나의 문장을 최소 기준 단어 수만큼으로 모두 쪼개어 저장한다. build in parser는 "안녕 나는 규코드야" 라는 문장을 안녕, 나는, 규코드야 3개의 토큰으로 구분짓지만, ngram 파서는 최소 토큰 설정값이 2라서 안녕,녕나,나는,는규, 규코 .. 와 같이 파싱한다. 검색을 할 수 있는 단어 기준이 더 다양해져서 결과를 얻을 확률이 더 커질 것 같다. 띄어쓰기와 상관없이 고정길이로 자르기 때문에 특히 한글 검색에 강할 것 같기도 하다.
참고!
* warning 메시지 : 1 warning(s): 124 InnoDB rebuilding table to add column FTS_DOC_ID
- InnoDB는 FULLTEXT 인덱스를 만들기 위해 내부적으로 테이블 구조를 변경한다고 한다. 이 과정에서 자동으로 FTS_DOC_ID라는 숨겨진 컬럼을 추가하여 문서를 관리한다.
SET SESSION cte_max_recursion_depth = 1000000;
CTE가 재귀 쿼리를 진행 할 때 최대 깊이는 넉넉히 100만으로 한정해둔다. 기본은 1000이라고 하니 더 많은 더미데이터가 필요하다면 깊이를 늘려야 한다. (출처)
https://dev.mysql.com/doc/refman/9.0/en/with.html
MySQL :: MySQL 9.0 Reference Manual :: 15.2.20 WITH (Common Table Expressions)
15.2.20 WITH (Common Table Expressions) A common table expression (CTE) is a named temporary result set that exists within the scope of a single statement and that can be referred to later within that statement, possibly multiple times. The following disc
dev.mysql.com

다른 프로젝트에서도 활용할 때 문제 없는 성능을 검증하기 위해서 한글과 영어가 섞인 컬럼 기사를 찾아서 저장시키려고 한다.
그리고 재귀 CTE를 정의해본다. content에 들어갈 컬럼 기사를 네이버 뉴스에서 임의로 복사해서 붙여넣었다.
INSERT INTO posts (title, content)
WITH RECURSIVE cte (n) AS (
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 100000
)
SELECT
CONCAT('Title ', n),
CASE
WHEN n % 7 = 0 THEN CONCAT('충혈은 결막 혈관이 확장돼 눈의 흰자위가 벌겋게 보이는 증상이다. 누구나 한 번쯤 겪어봤을 법한 증상이라 눈이 뻑뻑하면서 빨갛게 충혈되더라도 대수롭지 않게 여기기 쉽다. 일반인들은 흔히 눈이 충혈됐을 때 결막염을 의심한다. ')
WHEN n % 7 = 1 THEN CONCAT('젠슨 황 엔비디아 최고경영자(CEO)가 대만을 제2의 글로벌 본사 소재지로 낙점하고 슈퍼컴퓨터를 구축하는 등 본격적인 기반 마련에 나선 것은 세계 최대 파운드리(반도체 위탁 생산) 기업 TSMC와 전자제품 업체 폭스콘같이 인공지능(AI) 데이터센터 인프라를 위한 생태계가 잘 갖춰졌기 때문이다. ')
WHEN n % 7 = 2 THEN CONCAT('SK텔레콤 침해사고 민관합동조사단이 19일 정부서울청사에서 발표한 바에 따르면 악성코드 최초 설치 시점은 2022년 6월 15일이다. ', n)
WHEN n % 7 = 3 THEN CONCAT('규제 장벽에 둘러싸인 한국은 전 세계 시장에서 ‘모빌리티 혁신의 무덤’으로 불린다. ‘타다 사태’ 등 택시 업계의 반발에 부딪힌 정치권이 중재에 실패해 눈치만 보다 신사업이 무산되는 일은 반복되고 있다. ')
WHEN n % 7 = 4 THEN CONCAT('SK쉴더스는 아마존웹서비스(AWS)가 부여하는 경계 보안 인증인 레벨1 관리형보안서비스공급자(MSSP) 컴피턴시를 획득했다고 19일 밝혔다. AWS 레벨 1 MSSP 컴피턴시는 AWS 보안 서비스를 활용해 24시간 보안 모니터링, 위협 탐지·대응 등 핵심 보안 서비스를 제공하는 기업에 부여한다. ')
WHEN n % 7 = 5 THEN CONCAT('마이크로소프트(MS)·구글 등 글로벌 빅테크는 물론 네이버·카카오(035720)과 같은 국내 정보기술(IT) 기업들까지 ‘패스워드 리스’ 로그인 방식을 서둘러 도입하고 있다. 기술의 발전으로 해킹 시도도 고도화되고 있는 가운데 개인정보 탈취의 통로가 되는 비밀번호 자체를 없애 보안을 강화하겠다는 전략으로 분석된다. ')
WHEN n % 7 = 6 THEN CONCAT('20년이 넘은 지식재산권(IP) ‘마비노기’를 재해석한 ‘마비노기 모바일’의 이용자 수가 한 달만에 약 두 배 증가했다. 부담 없는 과금 구조와 따뜻한 게임 분위기가 초기 흥행을 견인한 것으로 분석된다. 넥슨은 마비노기 모바일처럼 올드 IP의 활용을 통해 지속적인 실적 개선을 이어가겠다는 전략이다. ')
ELSE CONCAT('데이터의 끝입니다. ')
END
FROM cte;
하나의 스크립트를 실행시킬 때 재귀 최대 depth 설정 쿼리와 CTE를 같이 실행시켜야한다. 그렇지 않으면 1000개만 생성된다!

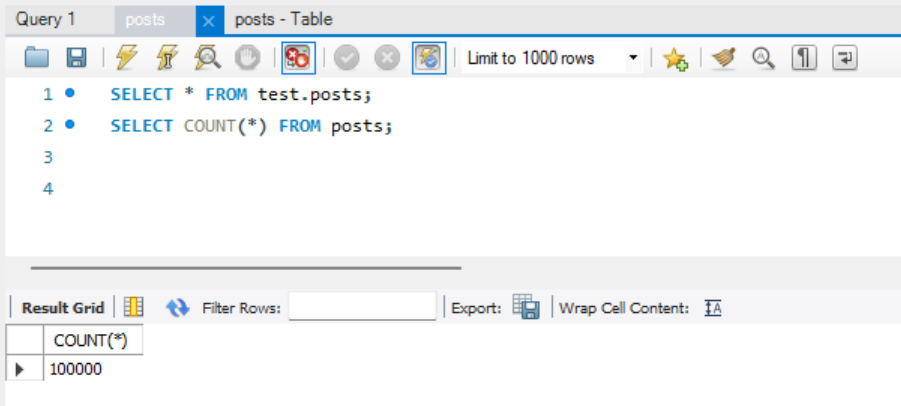
해당 쿼리를 실행시킨 결과 10만개 생성당 약 25초 정도가 소요된다. 총 10만개의 더미데이터를 만들었다.
FULLTEXT를 위해 INNODB 엔진이 자체적으로 생성한 뷰를 한번 확인해본다. 물리적으로 저장된 테이블은 아니고 시스템이 임의로 생성한 뷰 형태이다. 해당 과정을 통해 어떻게 단어들이 파싱되어 저장되어 있는지 확인하는 것이 목적이다.
아래는 시스템 변수로 설정해 내부적으로 접근한 뷰의 형태이다. 쪼개진 토큰이 해당 뷰 형태로 저장되는 것을 알 수 있다.
SET SESSION net_read_timeout = 120;
SET SESSION net_write_timeout = 120;
SET SESSION wait_timeout = 300;
SET GLOBAL innodb_ft_aux_table = 'test/posts';
SELECT * FROM information_schema.innodb_ft_index_table;
| WORD | FULLTEXT 인덱스에 저장된 단어(ngram 단위) |
| FIRST_DOC_ID | 이 단어가 처음 등장한 문서의 내부 ID (FTS_DOC_ID) |
| LAST_DOC_ID | 이 단어가 마지막으로 등장한 문서의 ID |
| DOC_COUNT | 이 단어가 등장한 문서 수 |
| DOC_ID | 이 행에 나타나는 특정 문서의 ID (자세한 위치 정보 포함) |
| POSITION | 해당 단어가 해당 문서 내에서 등장한 위치 (단어 단위 오프셋) -> 25번째의 위치에서 등장한다. |
full text 검색 방식에는 자연어 검색모드, Boolean 검색 모드, 쿼리 확장 모드로 3가지가 존재한다.
이 중에서 자연어 검색 모드를 활용해 full scan 검색과 응답 속도 차이를 비교해보겠다.
SELECT * FROM posts WHERE MATCH(content) AGAINST('젠슨') LIMIT 10000000;젠슨 이라는 이름이 담긴 문장이 있는 CONTENT를 조회해보았다. workbench gui에선 1000개 밖에 안보여서 LIMIT를 붙여서 전부 조회할 수 있도록 진행했다.

응답 결과 약 0.047초, 즉 47ms초만에 1만4천여개의 레코드를 찾아냈다.
다음으론 아무 인덱스가 걸리지 않은 동일한 테이블에서 젠슨을 조회해보겠다.

다음은 인덱스가 걸리지 않은 post2 테이블이다.
10만개의 동일한 데이터를 주입해 검색 쿼리를 실행해보겠다.
SELECT * FROM posts WHERE content LIKE '%젠슨%' LIMIT 10000000;
FULLSCAN을 진행하는데 0.140초, 즉 140ms초가 소요되었다. 약 66.43% 성능을 개선시킨 결과를 얻을 수 있었다.
수백만건, 수천만건의 데이터를 조회할 때 fulltext가 더 위력을 발휘할 것이다. ngram 파서를 활용할 경우 인덱스를 저장하기 위해 그만큼 저장공간을 소비하겠지만, 그만한 성능 결과를 얻을 수 있을 것이라 생각한다. 또한 모든 토큰을 저장시키지 않고 full text indexing 과정에서 제외하고 싶은 단어들을 지정하여 저장 공간을 절약할 수도 있다고 한다.
'Database' 카테고리의 다른 글
| 윈도우 함수 활용 ( ROW_NUMBER() ) (0) | 2025.02.10 |
|---|---|
| [ MYSQL ] 재귀쿼리 (0) | 2025.01.24 |
| SQL 쿼리 성능 최적화 방법 (1) | 2024.06.28 |
| [SQL] JOIN에서 WHERE과 ON 간 필터링 순서차이 (0) | 2024.02.13 |
| [SQL] BETWEEN과 연산자 부등호 성능 차이비교 (1) | 2024.02.04 |


